
We’ve all been there—using a Retrieval-Augmented Generation (RAG) system, thinking it will give us accurate answers, only to find bits of randomness thrown in. These “hallucinations” occur because traditional RAG systems, while helpful, have limitations. Fortunately, there’s a way to level up: integrating Knowledge Graphs with RAG. In this post, we’ll break down how Knowledge Graphs can solve the accuracy problem and when you should consider using them.
What’s Wrong with Traditional RAG Systems?
Traditional RAG systems have become a standard tool for answering complex queries by retrieving relevant chunks of text based on the question. While effective in certain scenarios, RAG systems often struggle with hallucinations, where the system generates responses that seem right at first glance but are actually misleading or incomplete.
For example, imagine you’re working with legal documents and asking your RAG system to retrieve information about a specific clause. You may get something close to the answer, but the system might also throw in unrelated text, confusing the results. This occurs because RAG’s approach lacks the necessary guardrails to ensure accuracy, leading to a retrieval process that sometimes fills gaps with irrelevant information.
This is where Knowledge Graphs can step in to enhance the retrieval process, reduce hallucinations, and provide more contextually accurate responses.
- RAG Systems Are Prone to Hallucinations:
- Retrieval-Augmented Generation systems are designed to pull chunks of text based on vector similarity. However, this can lead to hallucinations, where the system invents or incorporates irrelevant information.
- Knowledge Graphs Enhance RAG Accuracy:
- By creating connections between entities and their relationships, Knowledge Graphs provide additional context, which reduces the risk of hallucinations. This improves accuracy, especially for complex queries.
- Use Cases for Knowledge Graph RAG:
- Knowledge Graphs are particularly useful for datasets that are densely interconnected, like legal documents, technical manuals, and large wikis. Their ability to link entities across multiple sources ensures that key relationships and definitions aren’t missed.
- When Traditional RAG Might Be Enough:
- While Knowledge Graph RAG provides many benefits, it’s not always necessary. Simpler data sets or queries with low complexity may not need the added layer of a Knowledge Graph, and using a traditional RAG system might suffice in these cases.
How Knowledge Graphs Work with RAG
In a typical RAG system, the goal is to retrieve chunks of text that match the query, based on vector similarity. But this method has limitations, especially with complex queries. Enter Knowledge Graphs—a way to map out relationships between facts and entities to provide more accurate results.
Let’s say you’re working with a complex dataset, like a technical manual or a legal contract. A simple RAG system might retrieve information from multiple paragraphs that mention related topics, but miss out on the deeper, structured connections between terms or concepts. For instance, if you ask about how certain regulations impact safety measures, a traditional RAG system may pull information about both regulations and safety, but without showing how they interact.
A Knowledge Graph RAG organizes this information into nodes (entities) and edges (relationships). For example, the entity “Marie Curie” may have a relationship to the entity “Nobel Prize,” and that relationship is defined as “won.” This enables the system to pull precise facts—like “Marie Curie won the Nobel Prize twice”—without introducing irrelevant or incorrect information.
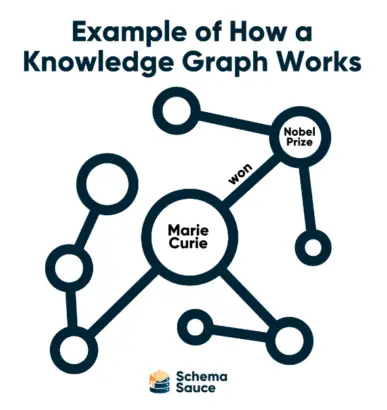
By providing structured relationships, a Knowledge Graph not only improves accuracy but also reduces redundancy, ensuring that results are clear and direct.
Where Knowledge Graphs Shine
Legal Documents and Contracts: Legal documents often have layers of clauses and cross-references. Knowledge Graphs are a perfect fit for this kind of data because they can capture the intricate relationships between different sections of a contract. Instead of retrieving isolated chunks, a Knowledge Graph can pull together the clauses, definitions, and references that truly answer the question.
Large Wikis and Technical Manuals: Wikis and technical manuals often have a high level of interconnectivity, with almost every paragraph linking to another page or section. In these environments, a Knowledge Graph is invaluable because it can trace connections across documents, ensuring that every piece of relevant information is brought to the forefront.
Glossaries and Complex Terms: If your dataset includes glossaries or complex technical terms, Knowledge Graphs ensure that every term is defined and linked to its usage throughout the document. This adds a layer of depth and clarity that traditional RAG systems would miss.
When Traditional RAG Is Enough
Knowledge Graphs are powerful, but they’re not always necessary. If you’re dealing with simple data structures, where the relationships between entities are minimal, traditional RAG systems are more than capable. For example, if your data set consists of FAQ-style documents or simple product descriptions, there’s no need to bring in the added complexity of a Knowledge Graph.
Additionally, if your resources are limited or your team isn’t familiar with graph databases, it might not be worth the learning curve for smaller or less complex use cases.
Check to See if Your Systems have a Graph API
You may have access to a Graph API from one of your systems and not even know it! Modern SaaS products serve (or should serve) API endpoints for their customers to pull and/or post data, but the most forward thinking product teams provide a Graph API to do the heavy lifting of entity mapping for you.
A traditional API (Application Programming Interface) typically provides a set of predefined endpoints for accessing specific data or functionality, often following a REST architecture. In contrast, a Graph API represents data as a collection of nodes and edges, allowing for more flexible and efficient querying of interconnected data.
Example: Microsoft’s Graph API is a prime example of this approach. It provides a unified endpoint for accessing various Microsoft 365 services and data, such as user profiles, emails, calendars, and documents. With Microsoft Graph API, developers can navigate complex relationships between different data types. For instance, a single query could retrieve a user’s profile, their recent emails, upcoming calendar events, and shared documents – all interconnected data that would typically require multiple calls in a traditional API setup. This graph-based structure allows for more intuitive and powerful data retrieval, enabling developers to build richer, more integrated applications that leverage the full ecosystem of Microsoft 365 services. Rounding this example to home, you could leverage the Graph API for making a RAG call to provide the most specificity and relevance when asking questions against your M365 calendar or emails.
Other systems like Customer Data Platforms, Content Management Systems, ERPs, etc. SHOULD have Graph APIs and if not… may be time to look for a new vendor.
